Community detection
In this section we applied different algorithms for community detection. By partitioning our network into communities we want to uncover hidden structure in the network and discover close relationships between our characters.
Louvain algorithm for community detection
We can detect communities using variety of methods. The below visualisation shows communities detected by Louvain algorithm. The great part is that it is interactive - you can zoom in to investigate the links in more detail, click on the nodes to highlight the links or even drag the nodes! For the sake of clarity, only the names of the most prominnet characters are displayed.Number of communities found is 9 and the corresponding modularity score is 0.36. In the context of this measure a partition is good when when there are many edges within communities and only a few between them [1] (nodes are densely connected within a community and sparsely connected with the rest of the graph [2]). According to [1], modularity above about 0.3 is a good indicator of significant community structure in a network in practice (network corresponds to a statistically surprising arrangement of edges).
One of natural questions that may come to one’s mind - can this partition be based on the branch that a character worked in? By investigating the above plot we can certainly say this is not the case, otherwise most of main characters should be assigned to one community representing Scranton branch. Let us then take a closer look at the most connected characters in each community.
Below presented are top 7 most connected characters (in terms of a total node degree in a full network) in each community, represented as a 2-column block (Name and Degree), which is repeated for every detected community. Direction of reading of the below table is therefore from left to right.
The aim is to see what are the most prominent members in each community, without distracting the reader with side- or guest characters that one might not recognize.
| Community 0 (n = 66) |
Community 1 (n = 32) |
Community 2 (n = 10) |
Community 3 (n = 25) |
Community 4 (n = 52) |
Community 5 (n = 39) |
Community 6 (n = 25) |
Community 7 (n = 6) |
Community 8 (n = 29) |
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Name | Degree | Name | Degree | Name | Degree | Name | Degree | Name | Degree | Name | Degree | Name | Degree | Name | Degree | Name | Degree |
| Michael Scott | 139 | Jim Halpert | 104 | Kevin Malone | 43 | Ryan Howard | 42 | Andy Bernard | 90 | Dwight Schrute | 118 | Jan Levinson | 52 | Dawn Tinsley | 11.0 | Phyllis Vance | 55 |
| Toby Flenderson | 51 | Pam Beesly | 101 | Stacy | 8 | David Wallace | 40 | Erin Hannon | 42 | Angela Martin | 52 | Michael Scarn | 12 | Tim Canterbury | 9.0 | Stanley Hudson | 27 |
| Meredith Palmer | 35 | Cecelia Halpert | 24 | Brenda Matlowe | 6 | Karen Filippelli | 27 | Kelly Kapoor | 40 | Oscar Martinez | 49 | Astrid Levinson | 9 | Gareth Keenan | 8.0 | Clark Green | 21 |
| Holly Flax | 34 | Helene Beesly | 16 | Pizza Delivery Kid | 6 | Nellie Bertram | 17 | Darryl Philbin | 38 | Pete Miller | 24 | Gil | 8 | Lee | 6.0 | Todd Packer | 19 |
| Creed Bratton | 27 | Roy Anderson | 16 | Abby | 5 | Charles Miner | 16 | Robert California | 33 | Mose Schrute | 11 | Goldenface | 7 | Keith Bishop | 4.0 | Bob Vance | 18 |
| Hannah Smoterich-Barr | 11 | Phillip Halpert | 15 | Lynn | 2 | Josh Porter | 12 | Gabe Lewis | 31 | Robert Lipton | 11 | Hunter Raymond | 7 | Donna (UK) | 3.0 | Cynthia | 9 |
| Louanne Kelley | 11 | Betsy Halpert | 13 | Melissa Riley | 2 | Alan Brand | 6 | Deangelo Vickers | 20 | Cameraman | 9 | Carol Stills | 6 | Teri Hudson | 9 | ||
Some of the key insights derived from the above table and visualisation:
- Michael Scott is a member of the biggest community (community 0), consisting of 66 people. It is reasonable that Holly Flax (Michael’s soulmate) is a member too. To our surprise, besides Meredith and Creed, who don’t seem to have many friends outside the Scranton Branch and even within it they did not establish many relationships, the rest of members of this community have low degrees.
- Community 1 seems to be the best defined as it is centered around the relationship betweem Jim and Pam and their families (we see characters with Beesly and Halpert surnames and Roy Anderson - former Pam’s fiancé).
- Community 2 is a small community centered around Kevin Malone as it includes his sister, daughter, and girlfriends.
- Community 3 consists of employees working in different Dunder Mifflin branches, usually occupying (at some point) managerial positions, including David Wallace - company CFO and later CEO - and his family.
Remaining communities include the rest of main characters in different proportions which is also dependent on how many different threads along the show they share. For example, in community 4 we have Dwight and Angela who had an affair at the beginning of the show. We also have Oscar who is an accountant just like Angela but he also had an affair with Angela’s husband - Robert Lipton!
Networkx algorithms for community detection
However, the modularity score is not as high as presented in [3] or [4], which suggests that the communities are not very well defined. Therefore, we tried other algorithms to see if they are more suitable for this type of network.
Two other algorithms that we tested:
greedy_modularity_communities- This function implements greedy modularity maximization algorithm described in [4] by Aaron Clauset, M. E. J. Newman and Cristopher Moore. It begins with each node in its own community and joins the pair of communities that most increases modularity until no such pair exists.async_fluidc- this function implements FLuid Communities algorithm desribed in [5] by Ferran Pares et al. It mimics the behaviour of several fluids (i.e., communities) expanding and pushing one another in a shared, closed and non-homogeneous environment (i.e., a graph), until equilibrium is found.
Below presented is a summary of modularities found by the three algorithms.
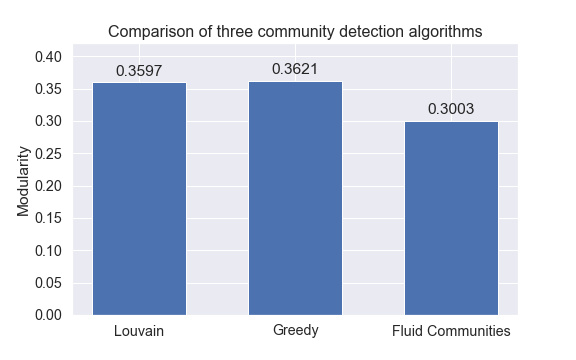
As can be seen from the summary above, we did not get significantly better results. We have a slightly higher modularity for a partition returned by a greedy algorithm. However, the difference is at the level of 0.003 which we might by eliminated by rerunning Louvain algorithm as it is a randomized method.
One reason behind not so high modularity value might be the bias in the network originated from wiki pages. We need to keep in mind that there is a tendency of mentioning only the most prominent characters in the description of every other character. It is understandable that the texts do not include every single encounter or interaction as this is not the purpuse of this website. But we must be aware this fact “skews” the network significantly towards main roles in our tv series.
But is that all we can do to understand the structure of communities in The Office? Of course not :D In the following section we’ll make use of our dialogues dataset to see if there’s something more to be discovered.
Weighted network based on dialogues
Our dialogues dataset contains every line ever said in The Office. We also know who said it, and in what season, episode and scene. We used this information to create a weighted network. A link between two characters is placed if they shared at least one scene and weight is the number of scenes shared.
The resulting network is presented below:
After running the three algorithms on a weighted network, we obtained the following results:
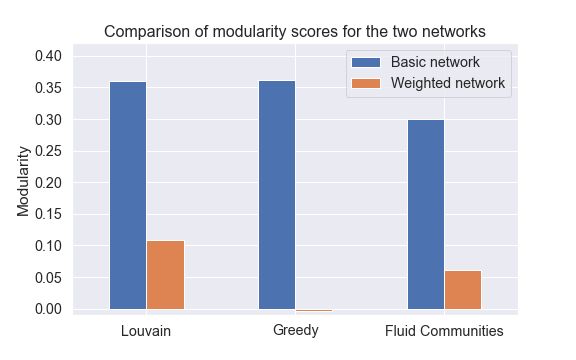
Unfortunately, the results are even worse than for the basic network, created from Wiki pages.
In the end, we would like to mention that we also extracted backbone of this network, as described in [5]. The aim was to create a reduced but hopefully more meaningful version of our initial weighted network and focus our attention only on the most significant connections to see if the community structure in such a representation will be better defined. The whole process is explained in the explainer notebook.
However, this procedure did not improve the modularity score. We can therefore conclude that most of the plot of The Office indeed focuses on the main characters and the interactions between themselves or the side characters, but we do not observe any relations between the side or supporting characters. This impacts the modularity score, because we have a lot of “satellite” nodes - characters that played in single scenes and whose links lead only to hubs or other side characters who by chance played in the same scene (it can be well observed in the visualisation of the full weighted network above).
References
[1] A. Clauset, M. E. J. Newman, C. Moore, (2004), “Finding community structure in very large networks”, DOI: 10.1103/PhysRevE.70.066111, https://arxiv.org/abs/cond-mat/0408187.
[2] F. Pares, D. Garcia-Gasulla, A. Vilalta et al. (2017), “Fluid Communities: A Competitive, Scalable and Diverse Community Detection Algorithm”, https://arxiv.org/abs/1703.09307v3.
[3] U. Brandes, D. Delling, M. Gaertler et al. (February 2008). “On Modularity Clustering”. IEEE Transactions on Knowledge and Data Engineering. 20 (2): 172–188. https://dx.doi.org/10.1109/TKDE.2007.190689.
[4] Newman, M. E. J. (2006). “Modularity and community structure in networks”. Proceedings of the National Academy of Sciences of the United States of America. 103 (23): 8577–8696. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1482622/.
[5] M. A. Serranoa, M. Boguñáb, A. Vespignani (2009), “Extracting the multiscale backbone of complex weighted networks”, https://www.pnas.org/content/pnas/106/16/6483.full.pdf.