Which characters use similar language?
In this section we will look at the similarities between the characters in terms of the language they use. Latent Dirichlet Allocation will help answer the question from the title. However, we used it in a somewhat unconventional way. Our aim was not to uncover K different topics that could easily be named as “accounting”, “company”, “IT”, “party”. This is not really possible to achieve with The Office dialogues - although there are some main threads that appear throughout many seasons and focus on relationships and operations of Dunder Mifflin Paper Company, every episode usually tells a completely different story. This impacts the vocabulary that our characters use in a way that it does not consist of K prevalent topics. In that sense LDA could do a much better job when used on a collection of documents with a limited number of specifiable topics.
So instead we used the identified topics (whatever they might be) to determine which of them are common for which characters. We performeded some sort of a clustering of documents representing our characters. Once we had the topics we could calculate the probability of a document being assigned to a given topic and that was the most useful information for our analysis.
In our implementation of LDA model, the input vocabulary was reduced by removing unrelevant words according to their TF-IDF value. For each document we defined a treshold being a 20% quantile of all TF-IDF scores in this document. Every word with a TF-IDF lower than the treshold was removed from a document. This way we pruned out words with no distinctive power, commonly used by most of the characters. This idea is described in [1].
We got the best coherence score for 3 topics. As mentioned before, there is no point in presenting the high-scoring words in each topic (although they are shown in the explainer notebook!). However, on the visualisation below we can clearly see that even though we cannot easily name the topics, they are well defined. Distance between the bubbles below tells us how similar the topics are and their size represents the importance of each topic over the entire corpus. We can see that the 3 detected topics are in fact very different from each other and quite similarly cover the entire corpus - that is there is not just one topic that dominates the rest, making them unrelevant.
Let us know visualise the distribution of topics over the documents for 15 main characters.
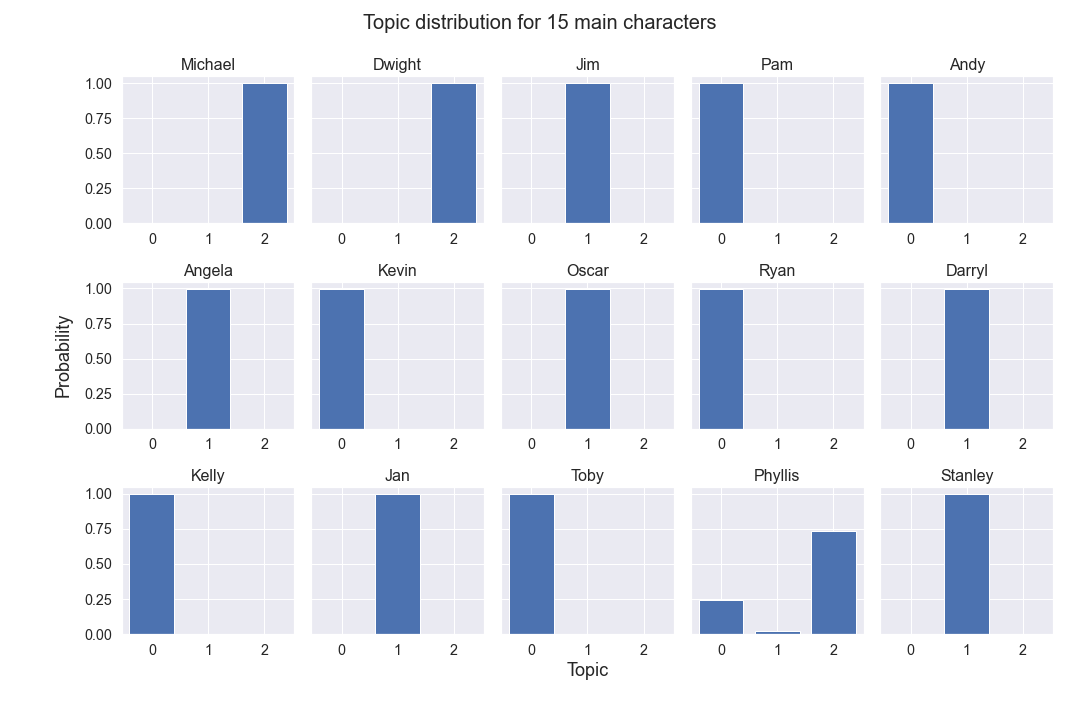
What is interesting, even though we set the hyperparameter responsible for a prior distribution over topic weights in each document to a higher value, almost all of the main characters were clearly assigned only one topic! It is only Phillis whose vocabulary is made up of two different topics. What we can see from the plot above is that Angela and Kevin share the same vocabulary - they are both accountants. And then we also have Stanley in the same cluster, who is indeed similar to Angela in that they both have rather negative attitudes, which is reflected in the sentiment analysis as well. Dwight and Michael are also in the same cluster, which might be explained by the fact that both are really interested in holding a managerial position.
Extra: Hellinger distance
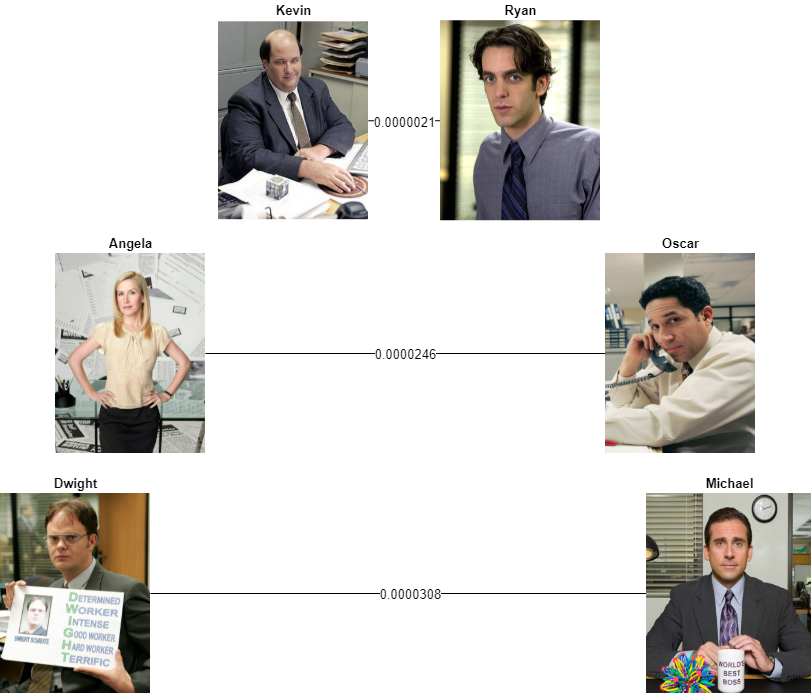
We thought it could also be interesting to actually measure what are THE MOST similar characters in terms of the vocabulary they use. For this purpose we will use Hellinger distance [2] - metric utilised in [1] - to calculate topic-based similarity measure between documents using posterior topic proportions. This measure can tell us a difference between two probability distributions P and Q. The output is between 0 and 1, where the maximum distance 1 is achieved when P assigns probability zero to every element to which the Q assigns a positive probability, and vice versa [2]. In our case P and Q are LDA topic distributions.
Below presented are top 3 pairs with the most similar vocabulary according to the described distance metric.
References
[1] D. M. Blei, J. D. Lafferty (2009), “Topic models”, http://www.cs.columbia.edu/~blei/papers/BleiLafferty2009.pdf.
[2] “Hellinger distance”, https://en.wikipedia.org/wiki/Hellinger_distance, [Accessed: 04.12.2021].